At Esperanto Technologies, we are interested in running generative AI models in ONNX format for three reasons:
1. ONNX is an interoperable format that allows two-way conversion to most other formats.
2. ONNX is supported by the ONNXRuntime framework, which is open-source and one of today’s main frameworks.
3. The ONNX format presents a static view of the models that is easier to load and optimize for Esperanto’s ML compiler, which leads to faster inferencing.
An ONNX file stores an implicit graph of operations. Vertices and edges of the graph are identified by operation and tensor names. The precise locations (i.e., names) can be found by inspection in the visualization tool Netron.
The figure showing the ONNX interoperability.
In this blog article, we will review the pipeline that we follow for converting a PyTorch Small Language Model (foundational, or fine-tuned) into a fully functional ONNX model using fp16 precision with Key-Value cache (KV-cache) support.
From PyTorch to ONNX
First of all, we assume that we have a Small Language Model (SLM: Transformer-based language models with less than 10 billion parameters) in the torch format, the format employed by PyTorch, the most widespread format for ML. Our first step will be to convert our torch model into a preliminary ONNX model using the torch.onnx.export command. For this, we need to provide inputs to the model so that we can trace the different operations that form the network.
A non-KV-cache-enabled SLM only requires two independent inputs: the input_ids, or the list of tokens that our prompt is converted to after tokenization, and the attention_mask, a mask that provides 1’s to the actual tokens that are being consumed and 0’s to padding. Only one output is needed for text generation, which is the “logits”. This output provides for each token in the input, one score for each token in the tokenizer’s dictionary that represent the predicted token likelihood distribution of the next position in the sequence. In a regular use case, we would ignore all but the last of these lists to predict one new token. When providing these inputs, we can also define “onnx_symbols” or dynamic_shapes, such as the batch or the sequence_length, which are placeholders that can adapt to the needs for the inference. These are particularly relevant to get different configurations from the same model (with different sequence length, batch, etc…). The last relevant flag for this conversion is the ONNX opset. As of September 2024, we can only guarantee that model with opset <=14 will be fully supported since some nodes’ definitions can vary drastically from an opset to the next.
So we finally get a command similar to the following:
dummy_input = torch.ones((1, 128), dtype = torch.int64)
symbolic_names = {0: "batch", 1: "sequence"}
torch.onnx.export(
model, #torch model
(dummy_input, dummy_input), #inputs
"model.onnx", #path of the output onnx model
input_names = ["input_ids", "attention_mask"],
output_names = ["logits"],
dynamic_axes = {"input_ids": symbolic_names, "attention_mask": symbolic_names, "logits": symbolic_names},
opset_version = 14
)
Once we obtain our preliminary model out of this command, we might want to tune it:
- Save the weights as external files.
- Convert the model to fp16, if the PyTorch model wasn’t already in fp16 precision. Note that when converting to fp16, we still want LayerNormalization performed using fp32 precision to give a higher dynamic range in those calculations.
- Change the output’s precision: if the PyTorch model was in fp16, the logits might still be converted to fp32. This can easily be modified by removing the Cast to fp32 in the last step of the ONNX.
Once all these steps are run, we can run inferences easily thanks to ONNXRuntime and verify that we have a fully functional ONNX model without KV-cache.
Adding KV-cache to SLMs
The language models under consideration all use the decoder-only Transformer architecture. In particular, these models operate with the embedded vectors representing different text tokens in parallel everywhere except at the self-attention layers. In those blocks, the auto-regressive nature of the models (in the sense that a new token is predicted taking into account only the past tokens) makes it possible to store intermediate results to reduce inference complexity. The cached tensors are known as keys and values.
We implement KV-caching using a sliding window approach. That is, only a range of a few tokens is processed by each inference of the model and this range moves as new tokens are generated. All the internal tensors of the model are cut accordingly, except at the self-attention layers where the embedded vectors representing past tokens are retrieved from the KV-cache.
Thus, the sequence length is replaced with several magnitudes:
- The window size is the number of tokens processed by one inference.
- The sequence length is the total number of tokens that the model can take into account in an inference. This is the length of an implicit sequence (possibly with padding at the beginning) that is made of the past tokens (implicitly stored in the caches) plus the window tokens.
- The maximum context length is the maximum number of tokens that the caches can store. This is useful in case one needs to increase the sequence length without moving the cached data.
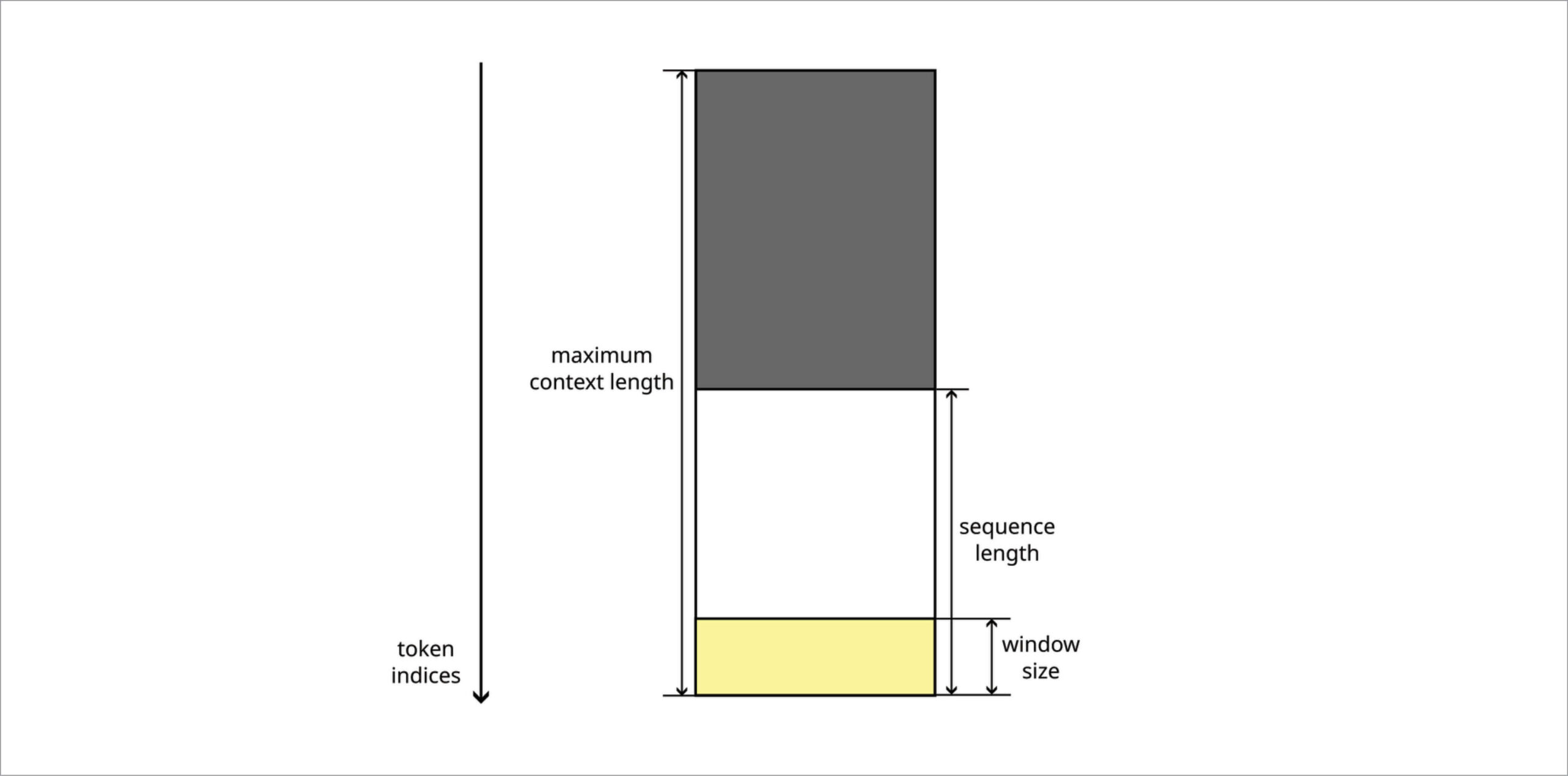
Simplified diagram of the KV-cache. In grey, padding. In yellow, the window filled by an inference.
The figure above shows the shape of a KV-cache tensor. As a matter of fact, this figure is a simplification because the lines corresponding to a token index are fragmented. The new model computes the yellow part, corresponding to the current window. To complete the picture, we add an input tensor for the white and grey parts (the past), an output tensor that represents the whole cache, an operation to concatenate all parts and another operation to extract the white and yellow parts (i.e., without the padding represented in grey). Esperanto Technologies’ ML compiler keeps the KV-cache tensor as a device-resident tensor, thus avoiding unnecessary data movement and copies.
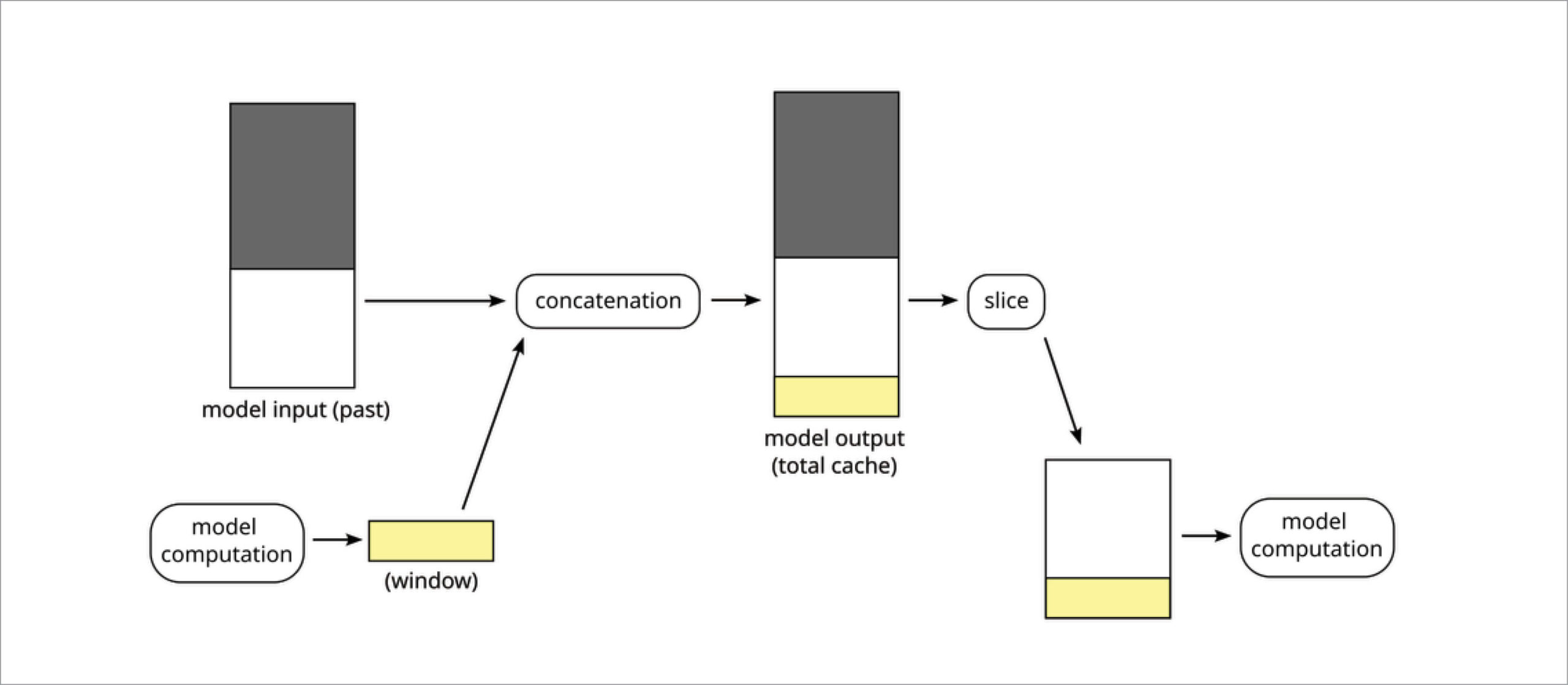
Operations added to form the keys/values tensors.
The input_ids tensor’s dimension corresponding to the sequence length is simply replaced with the window size. By ONNX’s shape inference, this change propagates to the rest of the model.

Change applied to the tensor of input tokens.
As for the attention mask, there are two tensors to consider. The mask applied to the self-attention blocks of the models is originally a square matrix of dimension equal to the sequence length. In the caching version of the model, only the last few rows (as many as the window size) of this matrix are used. In the simplest usage, auto-regressive language models are provided always with a triangular matrix known as causal mask, as it encodes that every token prediction depends on all the previous tokens. Then the input attention mask tensor is just a vector that the model internally expands as a matrix. That vector remains unchanged, but the part of the model that expands it has to be modified to use the right magnitude between the window size and the sequence length.
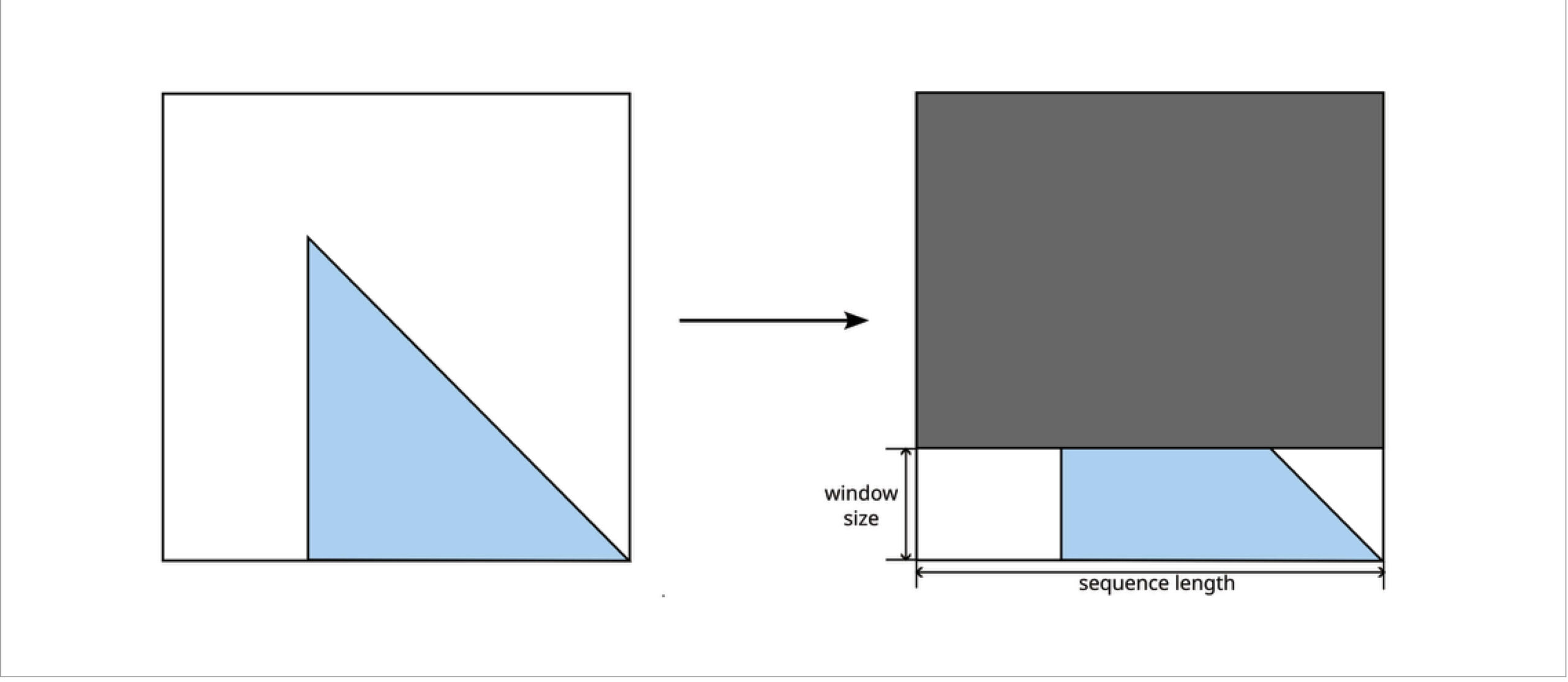
Change applied to the attention mask.
Rotary positional embeddings
Some SLMs include another piece that requires some careful modifications in our implementation: the rotary positional embeddings. This is a transformation applied to the queries and keys tensors of the self-attention layers before comparing them via dot products. Essentially, tokens are indexed starting from 0 and the embedded vectors corresponding to the k-th token are rotated by angles of the form kθ (for the queries) and -kθ (for the keys). When combining queries and keys in the self-attention, these rotations partially cancel each other. All in all, these operations capture how far apart two tokens are from each other inside the sequence.
The tokens inside the window cannot be indexed starting from 0 at every inference as the window slides. Rather, we modified the model so that the window is seen as the final part of the sequence (i.e., its first index is the sequence length minus the window size). Then it is crucial that the keys tensors are cached before applying the rotary embeddings transformations. In this way, even though the absolute index of a given token changes from inference to inference, the relative differences between indices are preserved and the model behaves as expected.
Conclusion
All the work described in this section is generic and can be applied to any SLM based on a transformers decoder-only architecture. At Esperanto, we advocate for the use of optimized ONNX models and to that end, we are committed to open-source as many SLM as possible, using different precisions, and extended to implement different optimization techniques. Note that these models can be used for any ONNX provider but they are specially modified to target the strengths of Esperanto’s products and achieve faster inference.
The Foundational SLMs that Esperanto has converted into ONNX in the fp16 precision can be found in our HuggingFace page.