Large Language Models (LLMs) are of great and growing importance across many industries, but their great size—hundreds of billions to trillions of parameters for some of the best-known examples—prohibits cost-effective deployment within most companies’ local IT infrastructure. Small Language Models (SLMs) are under active development by many companies to meet narrower requirements. SLMs focus on domain-specific knowledge rather than attempting to capture all human knowledge, preserving their value for business purposes while dramatically reducing their demands on computation, storage, energy, and carbon footprint.
In addition to reducing the size of a model, various other techniques can make commercial applications more practical. Some techniques focus on the architecture of SLMs to make them more efficient, others on hardware optimization.
Quantization, one of these techniques, has been widely studied. It is still an active area of research, nevertheless it is already capable of preserving high accuracy while reducing the memory need and the inference time by large factors—and it has been extensively industry-tested.
Such a behavior is enabled by billions of parameters and trillions of calculations for each word of the output. One major issue is mapping all these parameters into the most efficient areas of the memory system. This is where quantization kicks in.
Quantization reduces the precision of parameters and calculations while preserving enough accuracy to ensure that the model produces useful results. It allows us to store the same number in a smaller slot of memory. Typically, quantization maps a floating-point number to an integer using fewer bits of storage.
Understanding Quantization
Let’s start with understanding what quantization is and how it works. First, we need a quick reminder of how SLMs work. When one asks a natural-language question to an AI model, this question is converted to numbers that are fed to the model, which performs a series of calculations on them and yields another sequence of numbers that are converted back to natural language. If the model was correctly designed and trained, it should yield a useful answer.
Such a behavior is enabled by billions of parameters and trillions of calculations for each word of the output. One major issue is mapping all these parameters into the most efficient areas of the memory system. This is where quantization kicks in.
Quantization reduces the precision of parameters and calculations while preserving enough accuracy to ensure that the model produces useful results. It allows us to store the same number in a smaller slot of memory. Typically, quantization maps a floating-point number to an integer using fewer bits of storage.

Bits used for various data types
Quantization can be applied to various aspects of the SLM pipeline. In this blog post, we focus on the most frequent technique of quantizing weights, the coefficients that express the importance of each parameter in the eventual output of the model. Calculations are performed at a higher precision by dequantizing the weights right before calculations and requantizing them right after.
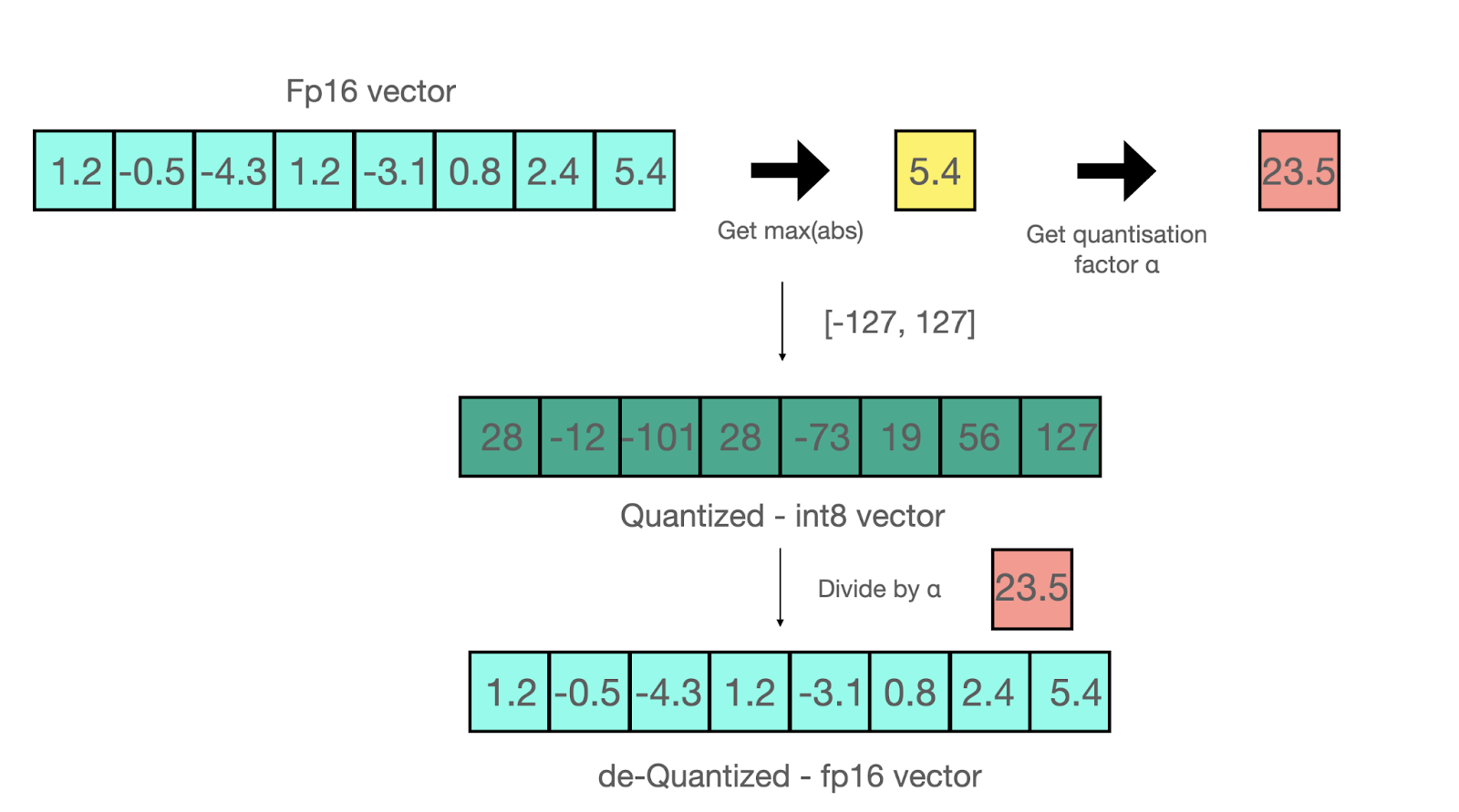
Example of quantization-dequantization. Note that in the general case some error is introduced. From: https://huggingface.co/blog/hf-bitsandbytes-integration
This dequantization-requantization process introduces some overhead, but most frameworks are memory bound rather than computation bound. In other words, it is the moving of numbers through different memory locations rather than the mathematical operations that limit the overall performance of the model. The overhead of dequantization-requantization is dwarfed by the gain from increasing bandwidth as expressed by the number of weights transferred per second.
Quantization can preserve useful accuracy even when decreasing precision from 16-bit floating point to 8, 6, 4, or sometimes even 2-bit integer representations. Thus, you can effectively reduce the size of a model by a factor of 2 to 8. Note that because of the reduced dynamic range of these integer representations, it is usually not possible to use them for training (gradients would break), making quantization an inference-only tool.
Common Methods
The whole idea of quantization can be summed up as finding a mapping from the floating point space to the n-bit integers space. The simplest way to do this is to use the round-to-nearest function after scaling the weights – for a set of parameters X it would look like this:
Q(X) = RTN((2**(n-1) -1) * X / absmax(X))
Where RTN is the round-to-nearest function, and n the number of bits selected. Other methods quantize weights using the tensors’ statistics in different fashions (e.g. zero-point quantization).
However, these statistics-based methods tend to have a quantization error (difference with original floating point parameters) that accumulates and yields bad output. To counteract this, more sophisticated quantitative algorithms have been developed, often based on solving an optimization problem of minimizing this error and include either a little bit of training or calibration on some data. We will now describe some widely-used quantization frameworks.
BitsAndBytes 4-bit (QLoRA)
The BitsAndBytes 4-bit quantization implements the method proposed by the QLoRA paper in May 2023. This method is inspired by the Quantile Quantization which proposes to partition the weights in same-size sets according to their distribution, effectively associating each weight with the index of its set. QLoRA’s authors further assume that in SLMs, the weights are roughly normally distributed and introduce a new data type: NormalFloat4. This data type is composed of 2**4 = 16 values, that are the 1/16-quantile of a normal distribution.
In this quantization, there is no calibration or training either as the weights are simply mapped to this set of values making it very fast to quantize a model on the fly. In addition, the algorithm was fully integrated into the extremely famous open-source framework HuggingFace – builders can quantize any SLM in a single snippet of code with the transformers library, making this method very popular.
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(‘mistralai/Mistral-7B-v0.3’,
load_in_4bit=True,
device=’cuda’,)
GPTQ
GPTQ method was introduced in late 2022, and proposes a more advanced and complex algorithm for quantizing SLM weights. This method is optimization-based and tries to minimize the quantization error:
argmin_W̃ (|| WX - W̃X ||)
Where W is the set weights, W^hat the quantized weights, X an input and ||.|| a norm metric. This is done layer by layer, ensuring that the overall performance of the model is preserved, while using Hessian calculations to guide the optimization process. One key insight is that the order in which weights are quantized doesn’t matter much for large models, which allows GPTQ to process weights in blocks, greatly speeding up the process. Additionally, GPTQ employs a technique called Cholesky decomposition to handle numerical inaccuracies, making it robust even for models with billions of parameters.
GPTQ can effectively quantize a model to 4 bits very quickly: it takes less than half an hour to quantize a 7B model to INT4 using 1xA100. Another perk of this method is that while it optimizes the quantization error, it does not assume anything about the quantization grid which can then be selected in any optimal way. Note that it requires a bit of training data to perform the optimization (the ‘X’ above), but the amount needed remains extremely low (a couple of hundreds of examples should do the trick) and for a foundation model any pre-training data will work just fine (RedPajama-2, The Pile, C4, …).
AWQ
AWQ (Activation-aware Weight Quantization) is from mid-2023 and proposes a newer quantization method. The authors make the observation that all weights do not have the same importance in a network but quantization usually applies the same transformation to all of them, making some quantization errors more impactful than others. To counteract this, they suggest protecting the weights responsible for outlier activations (which they call ‘salient’ weights). If they originally thought of keeping them in higher precision, they quickly dropped this idea as it would introduce low-level hardware complexity of mixed-precision matrix multiplications. Instead, they decided to protect the salient weight by scaling them before quantization by a factor s (un-scaling back after the quantization function). This trick reduces the quantization error by the factor ‘s’ and successfully limits the error on important weights.
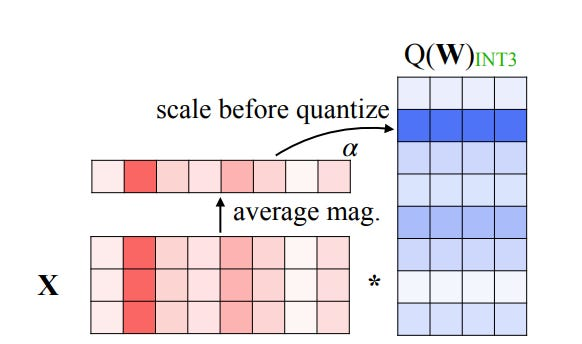
AWQ scaling. From: https://arxiv.org/pdf/2306.00978
The algorithm spots the salient weights using a small calibration dataset (a couple of hundred of examples from the pre-training dataset) and optimally chooses the s factor for each quantization block (solving a minimization problem). The amount of salient weights is a hyperparameter to select (usually between 0.1 and 1%).
AWQ provides excellent results for INT4 quantization and can go further. It is also relatively quick to apply, taking less than half an hour to quantize a 7B model to INT4 using a single A100 GPU. Furthermore, if you look closely, we did not define any quantization scheme per say i.e. AWQ is in fact an add-on for quantization and can be combined with any actual quantization method. The paper mentions that it can effectively quantize to 2 bits when combined with GPTQ for instance.
GGUF (llama.cpp)
The GGUF quantization format originates from the open source initiative llama.cpp. This github repository, written in pure C++, was built with the objective of running and serving SLMs efficiently locally on CPU. It now also supports GPU and incorporates a wide range of SOTA techniques that makes it extremely fast and memory efficient. In particular, the GGUF format allows quantizing any SLM to a lower bit representation.
While it is difficult to list exhaustively their tricks and quantization techniques (it is unfortunately not well-documented), we can still mention that they offer various quant precision (8, 6, 4, 2 bits and even continuous interpolations). We note that their global quantization pipeline is complex and uses multiple optimizations, in particular we can mention two major techniques that have proven very useful: some strategic layers throughout the network are voluntarily kept in higher precision to maintain a high level of accuracy, and they use a calibration dataset to minimize the quantization error similarly as aforementioned methods.
The llama.cpp framework makes SLMs accessible and reliable to anyone with a powerful CPU which justifies its popularity in the community.
Evaluation
At Esperanto, we decided to run our own evaluation of above-mentioned methods to create our pipeline with the most efficient framework. We selected Mistral-7B-Instruct-v0.2, one of the most famous and accurate SLMs, for our experiments. We evaluated the perplexity (the lower the better) of the quantized model for each method on a subset of Wikitext-2. Experiments were conducted on 1xA100 80GB HBM.
Note that all methods have their specificities and hyperparameters that can be tuned for optimal results, here we present the best results we could get and we mention the parameters used – but keep in mind that with further tuning, it’s likely that these numbers could be slightly improved.
| Model | Framework | Precision | Size (GB) | Inference Speed (tokens/s) | Perplexity (↓) | Quantization Details |
| Mistral-7B-Instruct-v0.2 | - | 16 bits (FP16) | 15.7 | 46.4 | 5.170 | - |
| BitsAndBytes (QLoRA) | 4 bits | 5.3 | 24.6 | 5.295 | NF4, Double Quantization | |
| GPTQ | 4 bits | 5.5 | 41.8 | 5.423 | Dataset: [128 2048-long samples from C4, Peak memory = 26Gb, time = ~30mn] Params: [Group=128, Act_order=False, True_sequential = True] | |
| AWQ | 4 bits | 5.3 | 46.9 | 5.276 | Dataset: [512 512-long samples from Pile dataset, Peak memory = 21Gb, time = ~28mn] Params: [Group=128, version=GEMV] | |
| GGUF (llama.cpp) | 4 bits | 4.9 | 91.7 | 5.245 | Q4_K_M |
Our benchmark led us to select primarily the AWQ quantization for our integration in ET-SoC-1 as it shows the best accuracy with an easily, flexible and usable framework directly integrated with the transformers library. Also note that GGUF offers the best raw performance, but its lack of clear documentation and weak integration with other open source frameworks (transformers) makes it difficult to use.
Converting to ONNX for ET-SoC-1 Integration
Let us recap the advantages of quantization:
As previously mentioned, LLMs are highly memory-bound problems, meaning that, in Inference time, more time and energy is spent moving data (especially weights) to where results will be computed than actually computing. Quantization is thus interesting since, if our weights are quantized to int4, for example, the memory footprint is divided by 4 relative to the fp16 representation and data movement is correspondingly reduced.
Of course this comes with costs: the first one is additional computing time since now our weights need to be converted back to fp16 precision before doing the actual calculations and the second cost is a loss of accuracy of the model due to the loss of precision in the weights.
Thankfully, performing these conversions does not slow down the inference since we are still in a memory bound problem. Overall, inference is faster. The second problem can be mitigated by using advanced quantization techniques, specialized in reducing the loss of accuracy in LLMs.
Like we mentioned in our previous section, at Esperanto we focus on the AWQ method (although the same procedure has been tested for GPTQ). First we need either an already AWQ quantized model, as those that can be found on Hugging Face (famous pages are The Bloke or TechxGenus) or we can quantize an fp16 model ourselves, thanks to the AutoAWQ package (part of the AutoGPTQ package).
Once our model is quantized, we can now convert it to ONNX. We often do this using an external tool called QLLM, which automatically converts and tests the model.
This model is obtained in a form that is not exactly the one that we like for our ONNX models so we use the same optimizations we used for fp16 models (described in detail in that blog post):
- Adding the Key-Value-Cache
- Adapting the Rotary Embeddings
- Adding the Context to extend our generation of tokens
- etc.
Conclusion
Quantization is a method that is very useful for speeding up LLM inference thanks to their memory-bound behaviour. The quantization error can be mitigated by used complex quantization techniques such as GPTQ, AWQ or GGUF.
At Esperanto, we are particularly interested in the AWQ technique and in order to support these quantized SLMs, we have converted to ONNX and ran a wide range of these models in our chip ET-SoC-1. The Foundational SLMs that Esperanto has converted into ONNX in the int4 precision thanks to the AWQ method can be found in our HuggingFace page.
Sources
LLM.int8(): https://arxiv.org/pdf/2208.07339
QLoRA: https://arxiv.org/pdf/2305.14314
GPTQ: https://arxiv.org/pdf/2210.17323
AWQ: https://arxiv.org/pdf/2306.00978
llama.cpp: GitHub – ggerganov/llama.cpp: LLM inference in C/C++